Multithreaded allocator
In Java, locks are used as a more flexible and sophisticated thread synchronization mechanism than the standard synchronized block. The Lock interface, available in the java.util.concurrent.locks package, provides extensive operations for locking. Some important methods of the Lock interface include:
- lock(): Acquires the lock if it’s available. If the lock isn’t available, a thread gets blocked until the lock is released.
- lockInterruptibly(): Similar to lock(), but allows the blocked thread to be interrupted and resume execution through a thrown java.lang.InterruptedException
A recommended code block to use the lock should contain a try/catch and finally block to ensure proper lock handling:
Another probably more useful tool, especially for this assignement, could be ReadWriteLock.
(Another solution to this problem is to build a custom memory manager that avoids locking conflicts. The simplest way of avoiding the conflicts would be for each thread to allocate objects on the stack rather thanin dynamic memory. From the performance standpoint that would be almost the ideal solution. However, this simplified approach is not always viable: thread stack size is limited and therefore allocating large objects or a large number of smaller objects on the stack is prohibited.)
A more practical approach is to provide a separate memory allocatorfor each thread ” a thread local allocator ” so that each allocator manages memory independently of the others. Most modern operatingsystems support the concept of per-thread storage, or a memory pool that is assigned to an individual thread. Thread-local storage provides a convenient way for different threads referring to the same global variable to actually refer to different memory locations, making the variable local to the thread.
A thread-local allocator associates a memory block with each threadand services the thread’s memory requests from this block, withoutinterfering with other threads’ allocation requests.
The custom thread-local allocator creates and maintains a number oflinked-lists (chains) of same-size blocks. Blocks are, in turn, madeout of “pages” allocated by a general-purpose memory manager {standardC-runtime malloc()in our case}. The pages are evenly divided into blocks of a particular size. Forexample, the allocator could, by default, create five chains with 32,48, 64, 128 and 256 byte blocks, each made out of 4K pages. Theallocator shown in our example below is optimized for the allocation ofsmall objects, but the page size, the number of chains, and the blocksizes can easily be changed to better fit application requirements.
Block allocator
Note: Problem with the solution presented in this source is that a block allocator is good when you have alot of reaccuring allocations of the same size (e.g. sensor readings that have same data size every time). This is not the case in our simulation as the size is randomized to a certain degree (see figure below).
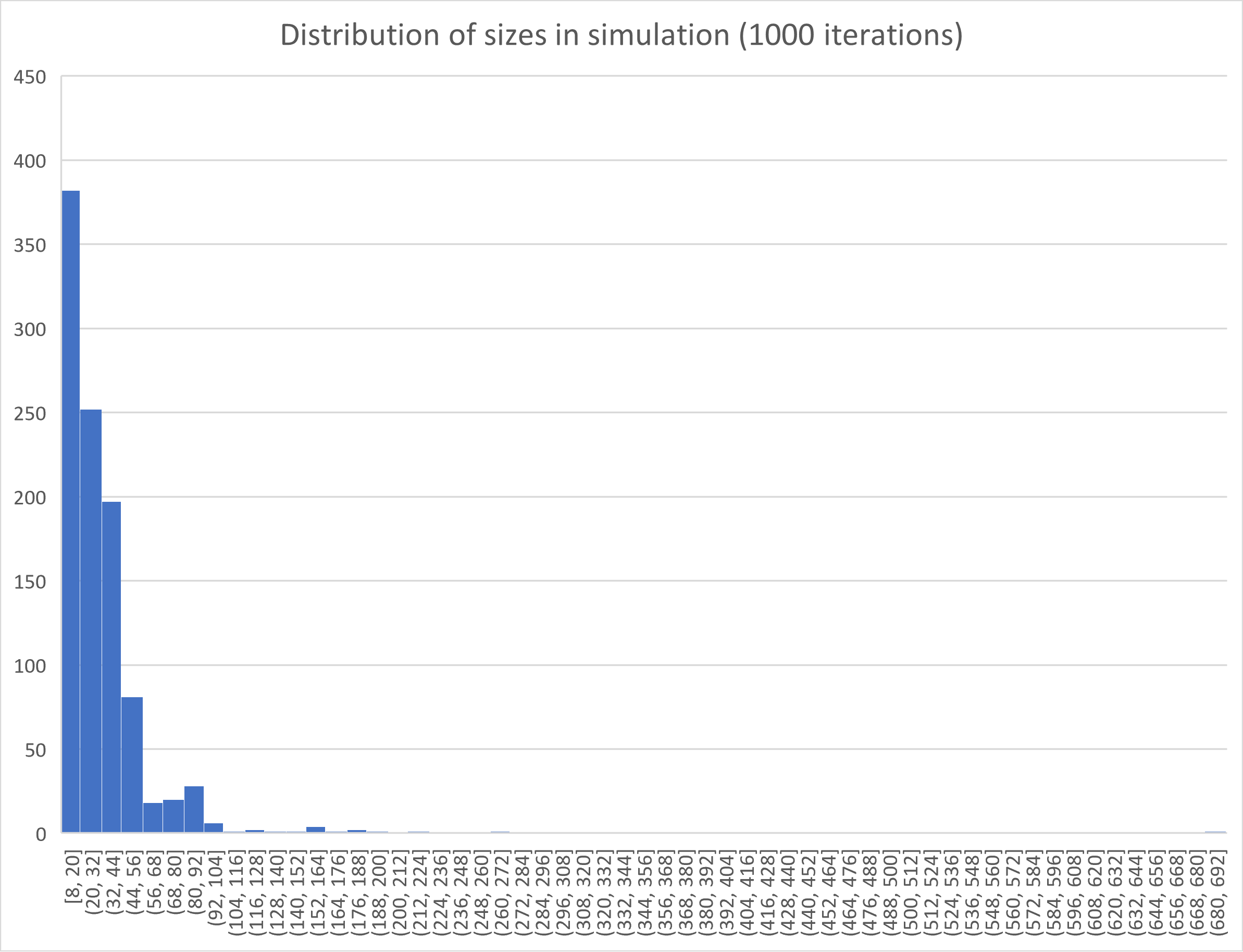
The case in which a block allocator could be used, thought not optimally: When the program asks for a certain allocation size, the block allocator will look for a the smallest size that is element of 2^k(=smallestSize). If there is none, we will call mmap(), and devide this block into smallestSize blocks. This way we limit the amount of mmap() calls. And keep just as many lists as necesary to also satisfy the larger blocks.
Realloc()
To statisfy the need of realloc() being possibly more performant than sequentially calling free() and alloc() we can threat a realloc() of a certain size as a multitude of the same size blocks as the size that was previously located on that address. An example to make this more clear:
alloc(100); //this gets put onto adress 0 in a linkedlist with block size 128
realloc(300); //check if the next two spots in the same linkedlist are free, if so, now mark these as not free
Note: This will only benefit performance for realloc()’s that are bigger than the initial alloc(). I would adhere from using a similar method of filling bigger sized blocks with smaller elements. This would cause alot of internal fragmentation. The downside to this is that there will be no possible performance gain for downsizing with realloc().
Making this multithreaded
Only a call for mmap() has to be synchronized. This will be performed by one specific thread. The linkedlist with specific addresses to that page will be handled by one thread only; this would be the one that initiaded it??? Yes!!! This will cause many pages that are not completely filled by blocks, as each thread can have their own page with 32,64,128,.. byte blocks.
What about deallocating
Pending-free request list(PRL’s) are maintained for each thread: when an object allocated in one thread is being de-allocated by another thread, the de-allocating thread link the object into the list of the thread that did the initial allocation. Access to the PRL’s is protected by a mutex. Each thread periodically de-allocates its share of object on the list at once.
The number of synchronization request is reduced significantly:
- often the object is freed by the same thread that had allocated it.
- when the object is de-allocated by a different thread, it does not interfere with all other threads, but only with those that need to use the same PRL.
My implementation
My current implementation works. Not yet optimalized:
- realloc(); it just calls free() and alloc().
- we free the pending request list every time we get in that specific thread. It might be more optimal to wait an arbitrary amount of time to free the PRL. We can keep an array of counters for every thread. When it exceed e.g. 100 iterations, we free it. This might decrease lock contention, but most of all the overhead of mode/context switching by alot since it has to be performed way less often.
- add read and write locks instead of synchronized